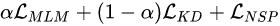金融
windows
磁盘已满
css3
sql
rabbitmq
均值算法
搜索引擎
趣味python
反射型XSS
MIT
synchronized
民商法
ThingsBoard
暴力
Pyhton
前沿技术
批量替换
数据内存对齐数
家谱
知识蒸馏
2024/4/11 14:54:55
知识蒸馏综述:网络结构搜索应用
【GiantPandaCV导语】知识蒸馏将教师网络中的知识迁移到学生网络,而NAS中天然的存在大量的网络,使用KD有助于提升超网整体性能。两者结合出现了许多工作,本文收集了部分代表性工作,并进行总结。
1. 引言
知识蒸馏可以看做教师网…
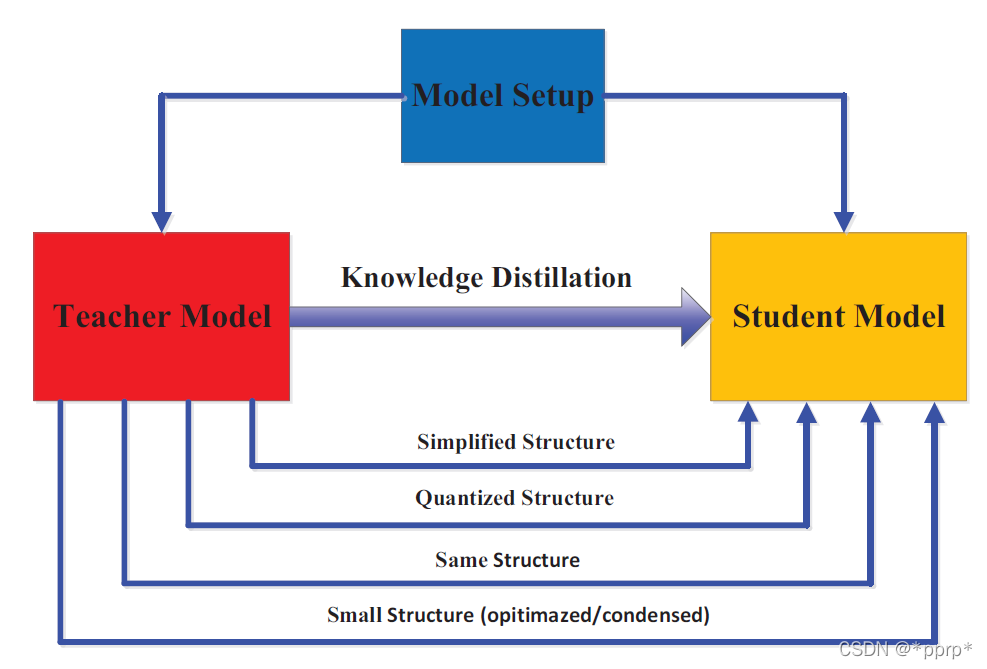
知识蒸馏综述:蒸馏机制
【GiantPandaCV导语】Knowledge Distillation A Suvery的第二部分,上一篇介绍了知识蒸馏中知识的种类,这一篇介绍各个算法的蒸馏机制,根据教师网络是否和学生网络一起更新,可以分为离线蒸馏,在线蒸馏和自蒸馏。
感性上…
人工智能|深度学习——知识蒸馏
一、引言
1.1 深度学习的优点 特征学习代替特征工程:深度学习通过从数据中自己学习出有效的特征表示,代替以往机器学习中繁琐的人工特征工程过程,举例来说,对于图片的猫狗识别问题,机器学习需要人工的设计、提取出猫的…
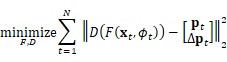
【论文阅读笔记】(2021 ICCV)Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
(2021 ICCV)
James Hong, Matthew Fisher, Michael Gharbi, Kayvon Fatahalian
Notes 写在前面(中文版自己总结)
之前的 AR(Actio…
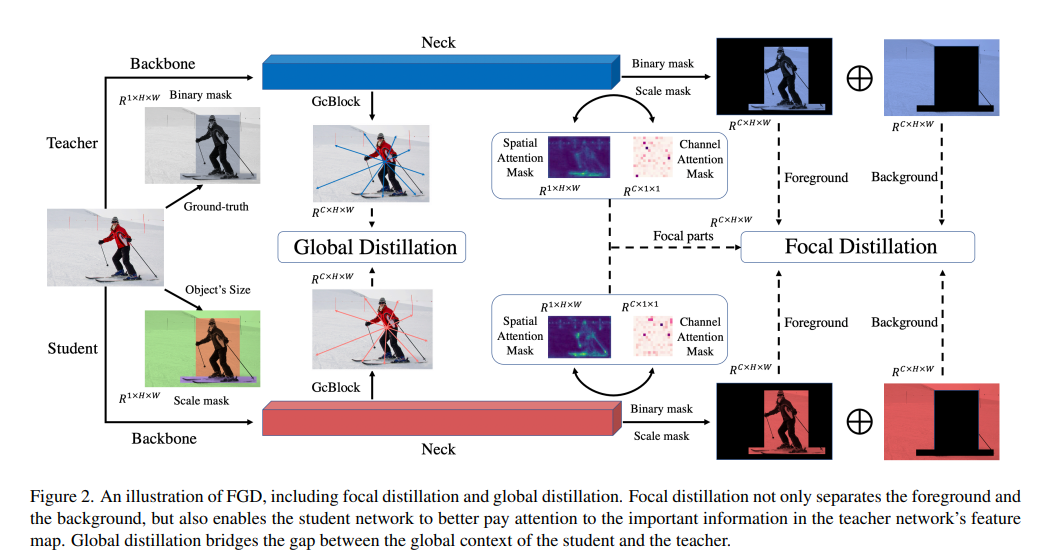
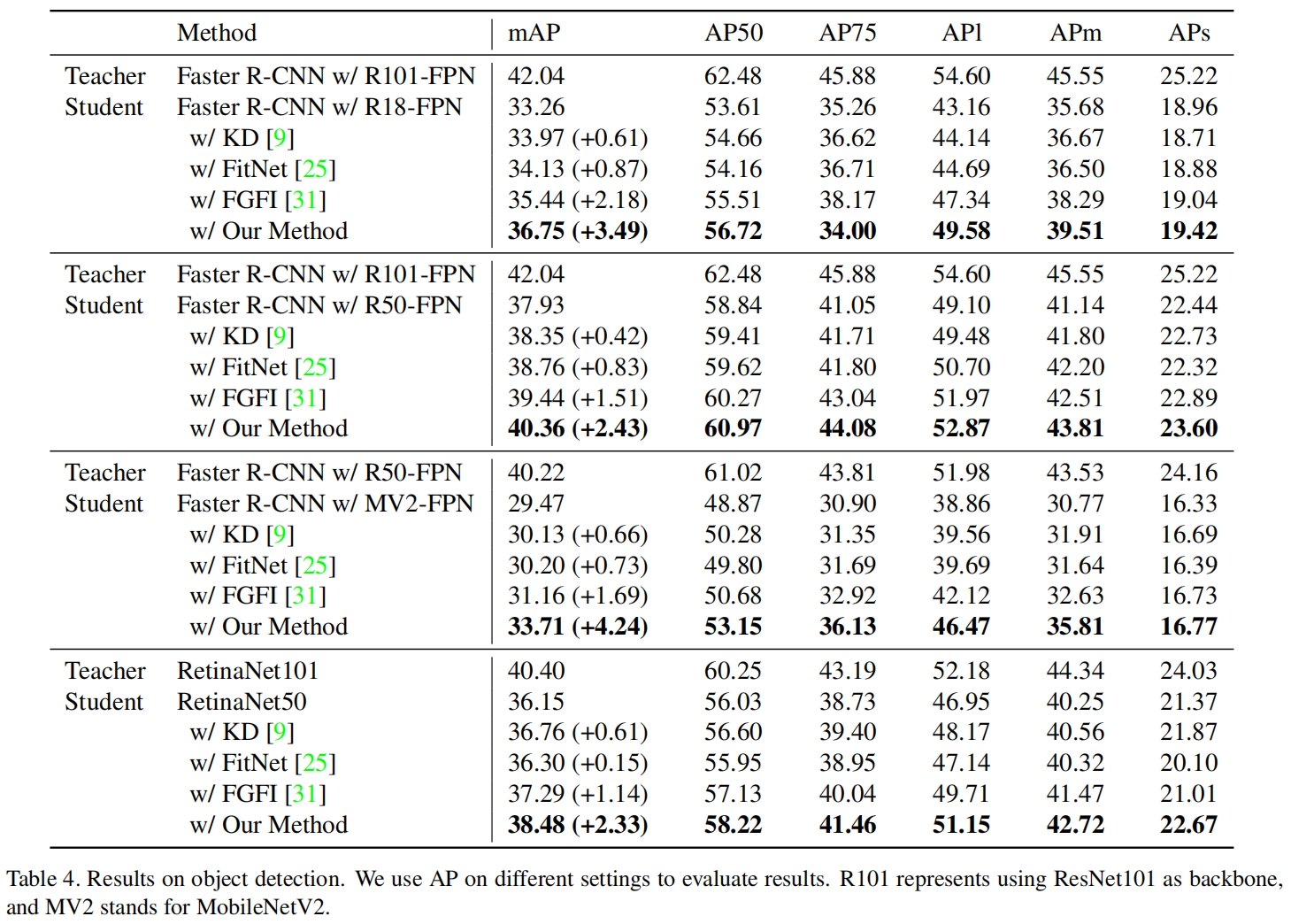
Featured Based知识蒸馏及代码(3): Focal and Global Knowledge (FGD)
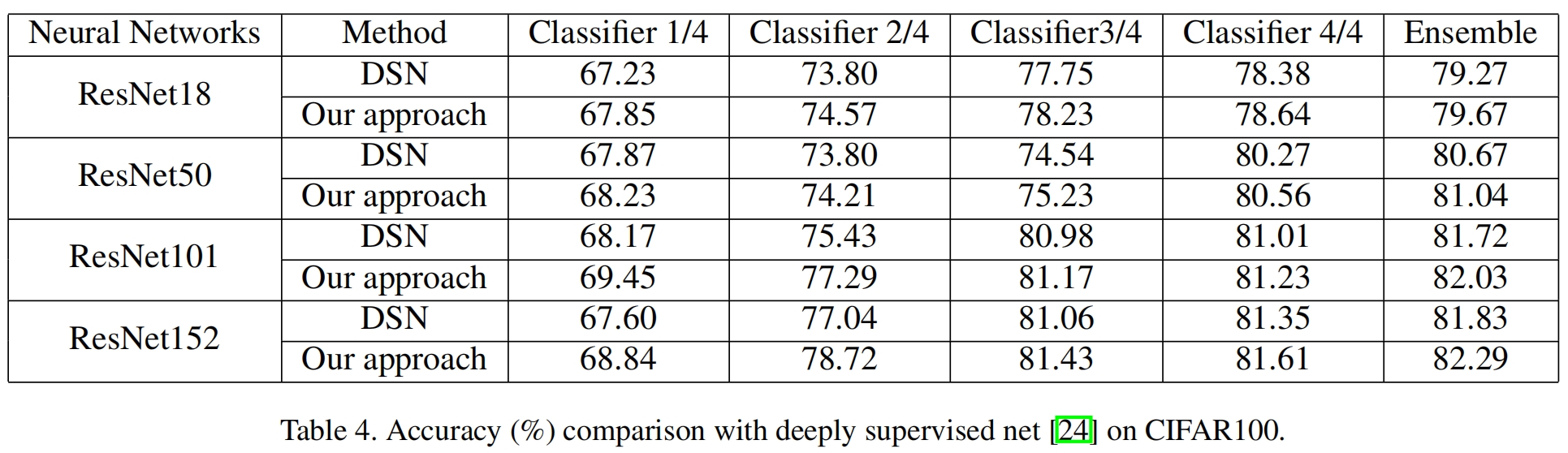
文章目录 1. 摘要2. Focal and Global 蒸馏的原理2.1 常规的feature based蒸馏算法2.2 Focal Distillation2.3 Global Distillation2.4 total loss3. 实验完整代码论文:
htt

yolov8知识蒸馏代码详解:支持logit和feature-based蒸馏
文章目录 1. 知识蒸馏理论2. yolov8 蒸馏代码应用2.1 环境配置2.2 训练模型(1) 训练教师模型(2) 训练学生模型baseline(3) 蒸馏训练3. 知识蒸馏代码详解3.1 蒸馏参数设置3.2 蒸馏损失代码讲解3.2.1 Feature based loss3.2.1 Logit loss3.3 获取蒸馏的feature map及channels
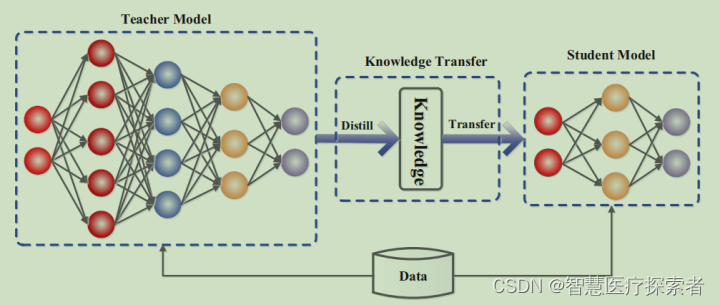
深度学习:什么是知识蒸馏(Knowledge Distillation)
1 概况
1.1 定义
知识蒸馏(Knowledge Distillation)是一种深度学习技术,旨在将一个复杂模型(通常称为“教师模型”)的知识转移到一个更简单、更小的模型(称为“学生模型”)中。这一技术由Hint…

个性化联邦学习-综述
介绍阅读的三篇个性化联邦学习的经典综述文章
Three Approaches for Personalization with Applications to Federated Learning
论文地址 文章的主要内容
介绍了用户聚类,数据插值,模型插值三种个性化联邦学习的方法。 用户聚类:
目的&a…

知识蒸馏博客阅读与理解学习
如何理解soft target这一做法? - YJango的回答 - 知乎 https://www.zhihu.com/question/50519680/answer/136406661
1. 是什么 2. 温度的作用
2.1 概述
2.2 举例 知识蒸馏:深入理解温度的作用 https://blog.csdn.net/weixin_39078049/article/detail…

知识蒸馏测试(使用ImageNet中的1000类dog数据,Resnet101和Resnet18分别做教师模型和学生模型)
当教师网络为resnet101,学生网络为resnet18时:
使用蒸馏方法训练的resnet18训练准确率都小于单独训练resnet18,使用蒸馏方法反而导致了下降。当hard_loss的alpha为0.7时,下降了1.1
当hard_loss的alpha为0.6时,下降了1.7说明当学生…

论文解读:Masked Generative Distillation
文章汇总 话题 知识蒸馏 创新点 带掩盖的生成式蒸馏 方法旨在通过学生的遮罩特征来生成老师的特征(通过遮盖学生部分的特征来生成老师的特征),来帮助学生获得更好的表现 输入:老师:,学生:,输入:,标签:,超参数: 1:使…

针对(分为子结构的)结构性预测的知识蒸馏(可用于ner)(ner知识蒸馏)
一般的知识蒸馏 词级别知识蒸馏 结构知识蒸馏
实际上不同位置的输出往往并不是相互独立的,比如用 BIOES 标注 NER 标签的例子:“希尔顿离开北京机场了”,其标签为”B-PER, I-PER, E-PER, O, O, B-LOC, I-LOC, I-LOC, E-LOC, O“。I 标签前只…

知识蒸馏综述: 知识的类型
【GiantPandCV引言】简单总结一篇综述《Knowledge Distillation A Survey》中的内容,提取关键部分以及感兴趣部分进行汇总。这篇是知识蒸馏综述的第一篇,主要内容为知识蒸馏中知识的分类,包括基于响应的知识、基于特征的知识和基于关系的知识…

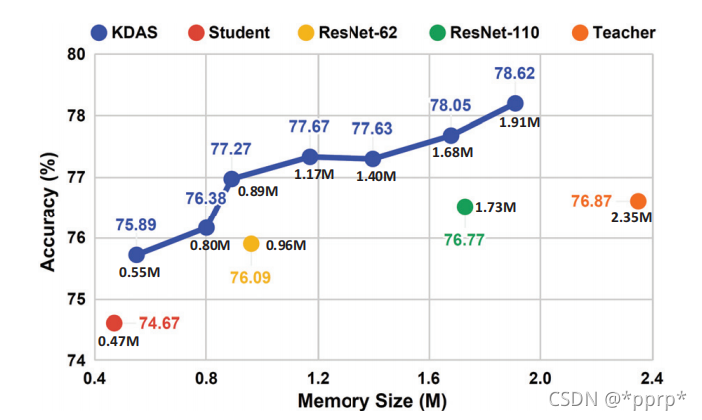
Towards Oracle Knowledge Distillation with NAS
【GiantPandaCV导语】本文介绍的如何更好地集成教师网络,从而更好地提取知识到学生网络,提升学生网络的学习能力和学习效率。从方法上来讲是模型集成神经网络结构搜索知识蒸馏的综合问题,在这里使用简单的NAS来降低教师网络与学生网络之间的差…
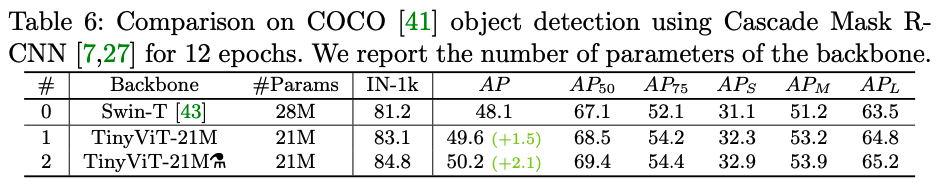
tinyViT论文笔记
论文:https://arxiv.org/abs/2207.10666 GitHub:https://github.com/microsoft/Cream/tree/main/TinyViT
摘要
在计算机视觉任务中,视觉ViT由于其优秀的模型能力已经引起了极大关注。但是,由于大多数ViT模型的参数量巨大&#x…

温故而知新的知识蒸馏 Distilling Knowledge
文章目录温故而知新的知识蒸馏温故而知新的知识蒸馏
博客链接:Knowledge Review:超越知识蒸馏,Student上分新玩法! 上图中的(d)是提出的新方法,他融合了Teacher的不同层。 原因:之…
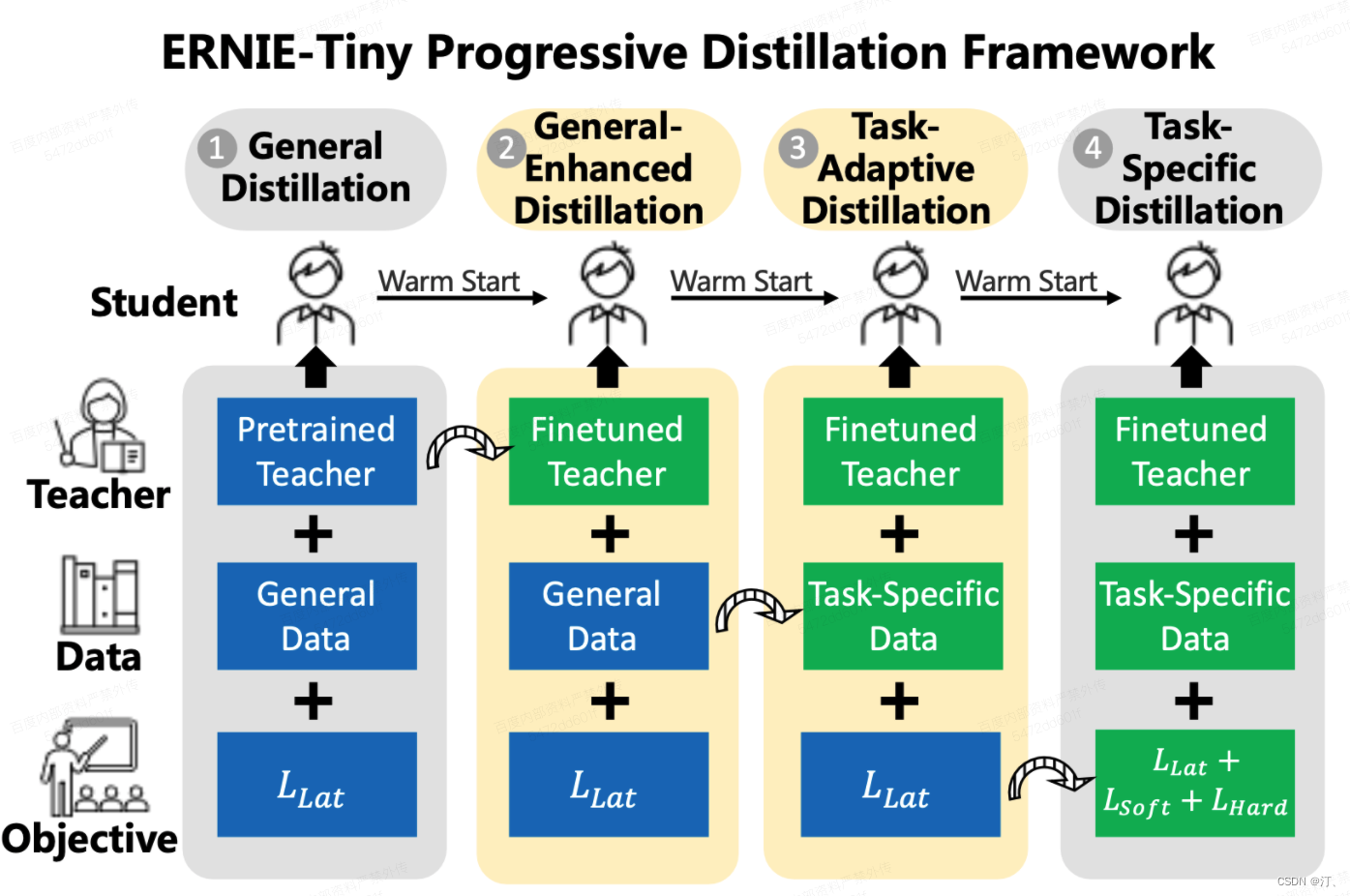
知识蒸馏相关技术【模型蒸馏、数据蒸馏】以ERNIE-Tiny为例
1.任务简介
基于ERNIE预训练模型效果上达到业界领先,但是由于模型比较大,预测性能可能无法满足上线需求。 直接使用ERNIE-Tiny系列轻量模型fine-tune,效果可能不够理想。如果采用数据蒸馏策略,又需要提供海量未标注数据ÿ…
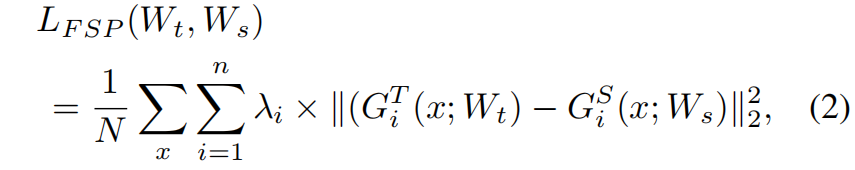
FSP:Flow of Solution Procedure (CVPR 2017) 原理与代码解析
paper:A Gift From Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learningcode:https://github.com/HobbitLong/RepDistiller/blob/master/distiller_zoo/FSP.py背景深度神经网络DNN逐层生成特征。更高层的特征更接近…

ICLR2021清华团队做的知识蒸馏提升detector的点的工作paper 小陈读论文系列
这个作者栏目就是一个词 清爽 牛逼不需要花里胡哨哈哈 无疑是有点tian了哈哈 不重要
毕竟有机会研读 梦中情笑的paper 还是很感激的 真的 很清爽啊
很多KD的工作确实 在下游任务呢效果不是很好
然后就引出了自己的关于提升知识蒸馏在OD方面的工作
OD 首先就有两个问题 1.前…

Distilling Knowledge via Knowledge Review(引言翻译)
翻译得可能不太准确,希望有能力的各位批评指正! Introduction
第一段
深度卷积神经网络(CNN)在计算机视觉多数任务中取得了显著的成功。
然而,卷积网络的成功往往伴随着相当大的计算和内存消耗,
使得将…
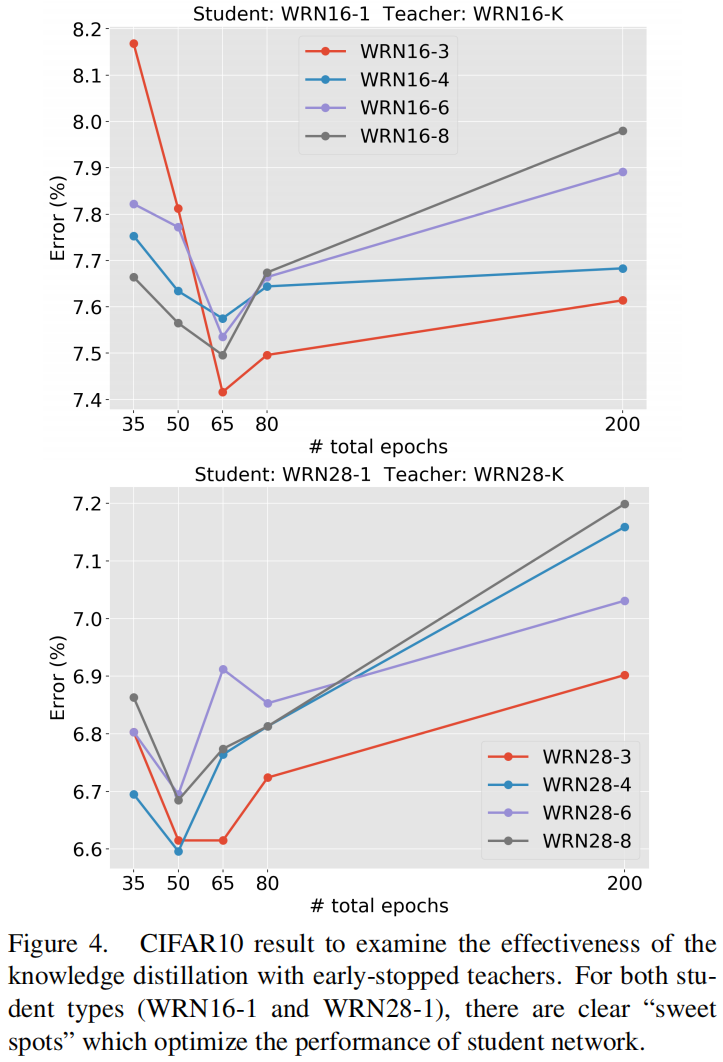
On the Efficacy of Knowledge Distillation 解析
paper:On the Efficacy of Knowledge Distillation
本文的题目是《论知识蒸馏的有效性》,主要是对教师模型并不是越大越好这一现象进行研究,并提出了缓解方法:early stop。
Bigger models are not better teachers
知识蒸馏背…
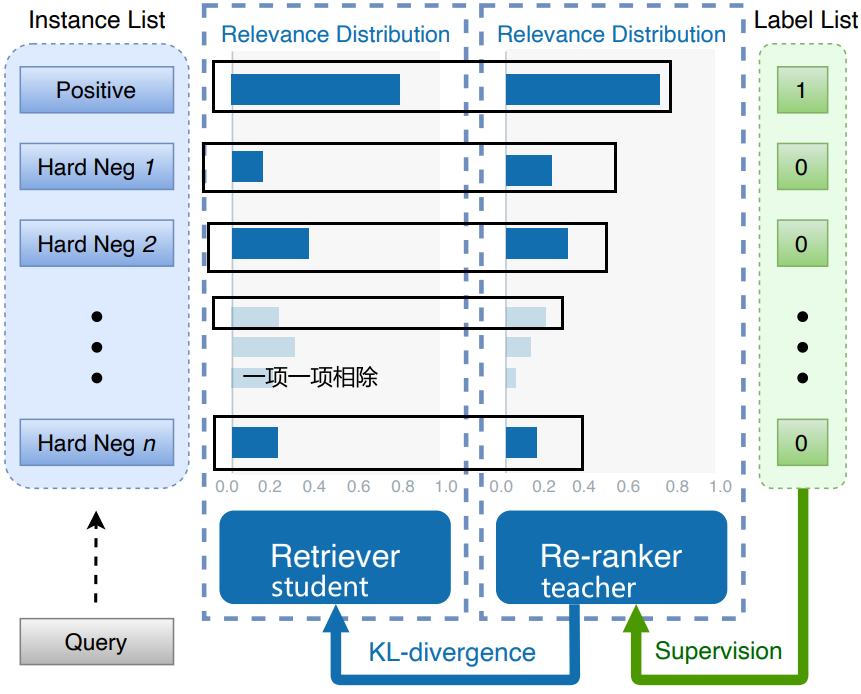
知识蒸馏Matching logits与RocketQAv2
知识蒸馏Matching logits
公式推导
刚开始的怎么来,可以转看下面证明梯度等于输出值-标签y C是一个交叉熵,我们要求解的是这个交叉熵对的这个梯度。就是你可以理解成第个类别的得分。就是student model,被蒸馏的模型,它所输出的…
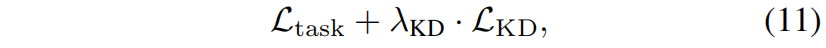
Relational KD(CVPR 2019)原理与代码解析
paper:Relational Knowledge Distillationcode:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/RKD.py背景本文从语言结构主义的角度来重新审视知识蒸馏,前者主要关注一个符号学系统中的结构关系。索续尔…
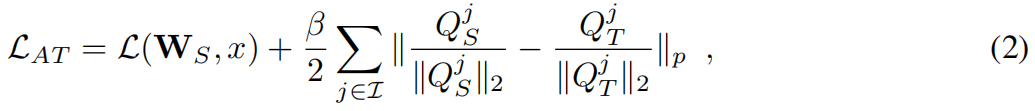
基于注意力的知识蒸馏Attention Transfer原理与代码解析
paper:Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfercode:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/AT.py背景一个流行的假设是存…
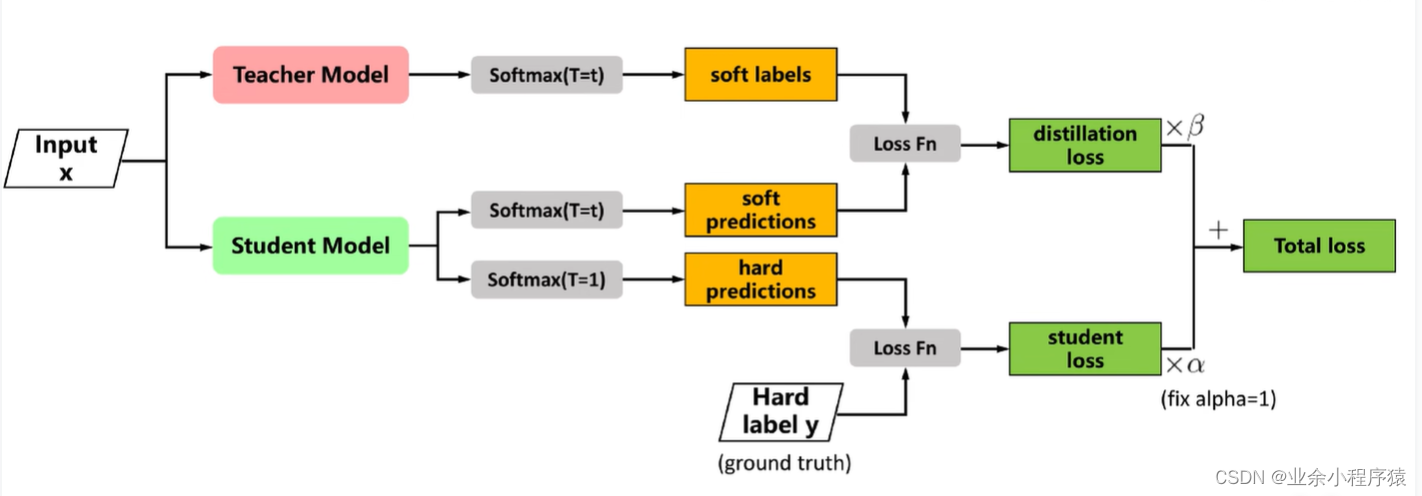
知识蒸馏实战代码教学二(代码实战部分)
一、上章原理回顾 具体过程: (1)首先我们要先训练出较大模型既teacher模型。(在图中没有出现) (2)再对teacher模型进行蒸馏,此时我们已经有一个训练好的teacher模型,所以…
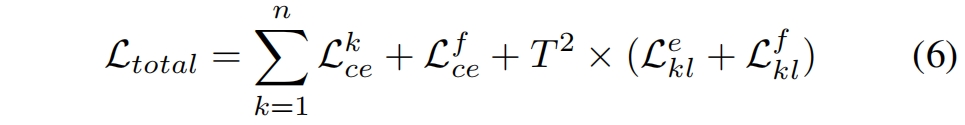
Feature Fusion for Online Mutual KD
paper:Feature Fusion for Online Mutual Knowledge Distillation
official implementation:https://github.com/Jangho-Kim/FFL-pytorch
本文的创新点
本文提出了一个名为特征融合学习(Feature Fusion Learning, FFL)的框架&…
Self Distillation 自蒸馏论文解读
paper:Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
official implementation: https://github.com/luanyunteng/pytorch-be-your-own-teacher
前言
知识蒸馏作为一种流行的压缩方法&#…

论文解读:在神经网络中提取知识(知识蒸馏)
摘要
提高几乎所有机器学习算法性能的一种非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均[3]。不幸的是,使用整个模型集合进行预测是很麻烦的,并且可能在计算上过于昂贵,无法部署到大量用户&#x…
Knowledge Review(CVPR 2021)论文解析
paper:Distilling Knowledge via Knowledge Review
official implementation:https://github.com/dvlab-research/ReviewKD
前言
识蒸馏将知识从教师网络转移到学生网络,可以提高学生网络的性能,作为一种“模型压缩”的方法被…

CRD3 小陈读paper
KD损失 比较常见了 对于源模态上的原始训练任务,此类数据没有真实标签 y,因此我们忽略我们测试的所有目标中的 H(y, yS ) 项。 这个比较适合看图 Experiments
我们在三个知识蒸馏任务中评估我们的对比表示蒸馏 (CRD) 框架:
(a&a…
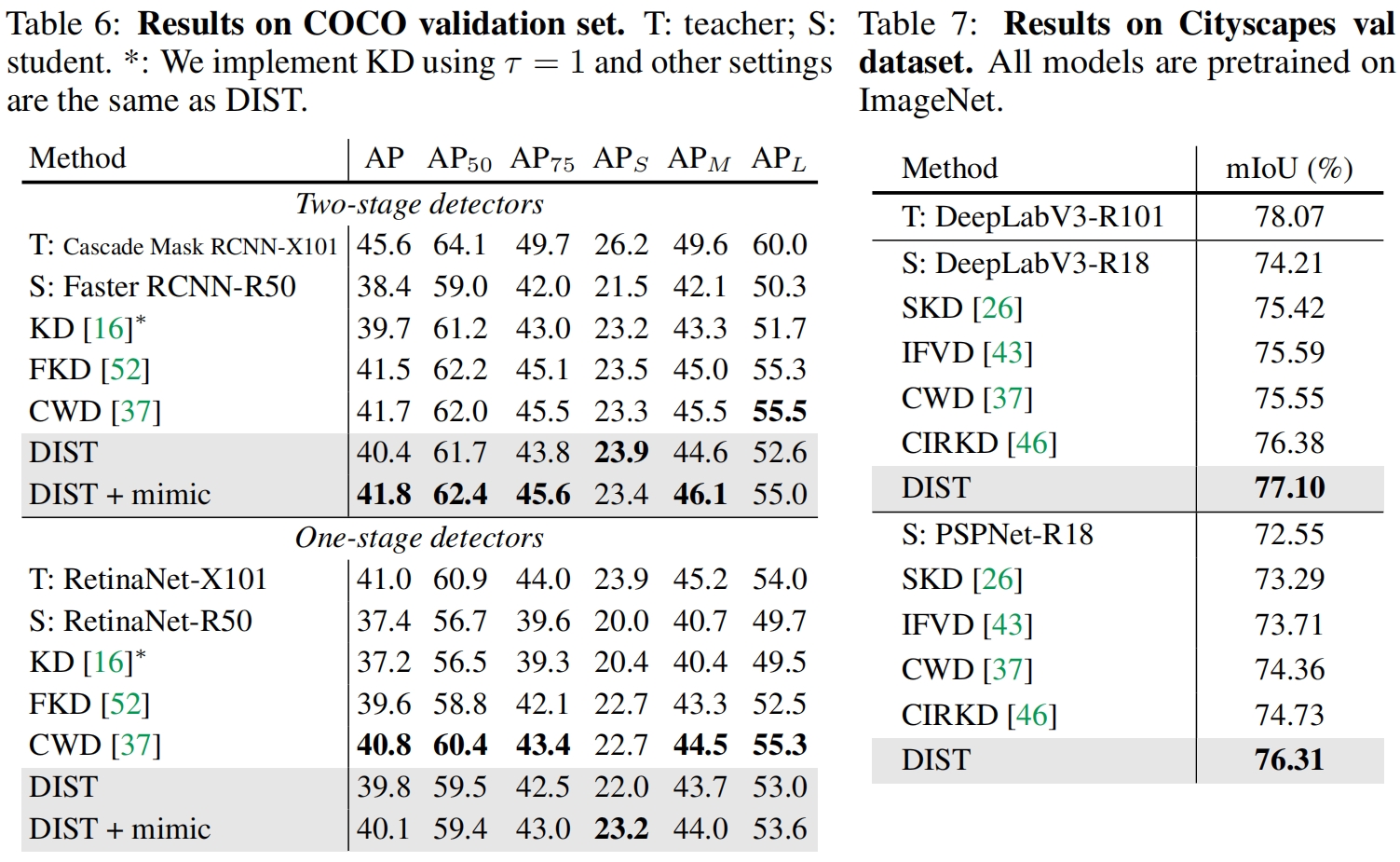
Knowledge Distillation from A Stronger Teacher(NeurIPS 2022)论文解读
paper:Knowledge Distillation from A Stronger Teacher
official implementation:https://github.com/hunto/dist_kd
前言
知识蒸馏通过将教师的知识传递给学生来增强学生模型的性能,我们自然会想到,是否教师的性能越强&…

Improved Knowledge Distillation via Teacher Assistant小陈读paper系列
算是经典了吧哈哈
1.他们发现了学生性能下降了,什么时候呢?就是老师模型和学生模型差的太多的时候有了很大gap(一个学生不能请一个维度跨越巨大的老师)(老师可以有效地将其知识转移到一定大小的学生,而不是…

对知识蒸馏的一些理解
知识蒸馏是一种模型压缩技术,它通过从一个大模型(教师模型)中传输知识到一个小模型(学生模型)中来提高学生模型的性能,知识蒸馏也要用到真实的数据集标签。
软损失soft loss就是拿教师模型在蒸馏温度为T的…

CRD2 值得一读的知识蒸馏与对比学习结合的paper 小陈读paper
一定要读 真的是不一样的收获啊
不知道 屏幕前的各位get到了没有
Hinton et al. (2015) introduced the idea of temperature in the softmax outputs to better represent smaller probabilities in the output of a single sample.
Hinton等人(2015)引入了softmax输出中温…